 021-80120081
021-80120081免费服务热线
一年两度的 Linley 处理器峰会(Linley Processor Conference)聚焦于探讨 AI 应用程序、嵌入式、数据中心、汽车、物联网、通信和服务器设计领域的业界发展与技术应用。
今年的Linley 春季处理器峰会(Linley Spring Processor Conference)已于4月举行。值得一提的是,此次会议的主办方 Linley Group(科技行业权威咨询机构) 已于去年10 月被总部设在加拿大的 TechInsights 公司收购。正如在宣布收购的新闻稿中提到:
“多年来,我们与 Linley Group 进行了多次合作。我们的关注方向一致,Linley Group 的微处理器架构评论与 TechInsights 的微处理器深度技术分析相辅相成。在 TechInsights 平台上增加 Linley Group 的报告将为我们的客户带来更丰富的内容,特别是对微处理器感兴趣的客户。”——TechInsights 首席执行官 Gavin Carter

Linley Gwenapp 在峰会第一天发表了题为《边缘人工智能发展趋势》的主题演讲,本文将对该演讲进行介绍与讨论。
人工智能发展加速的三大趋势
1、模型增长速度不同
在《边缘人工智能发展趋势》的主题演讲中,Linley 展示了 2021 年模型的增长速度。人工智能发展加速的第一个趋势即是成像模型和自然语言处理 (natural language processing ,即NLP) 模型的情况大不相同。在下图中,成像模型用黑色表示,NLP 模型用红色表示。
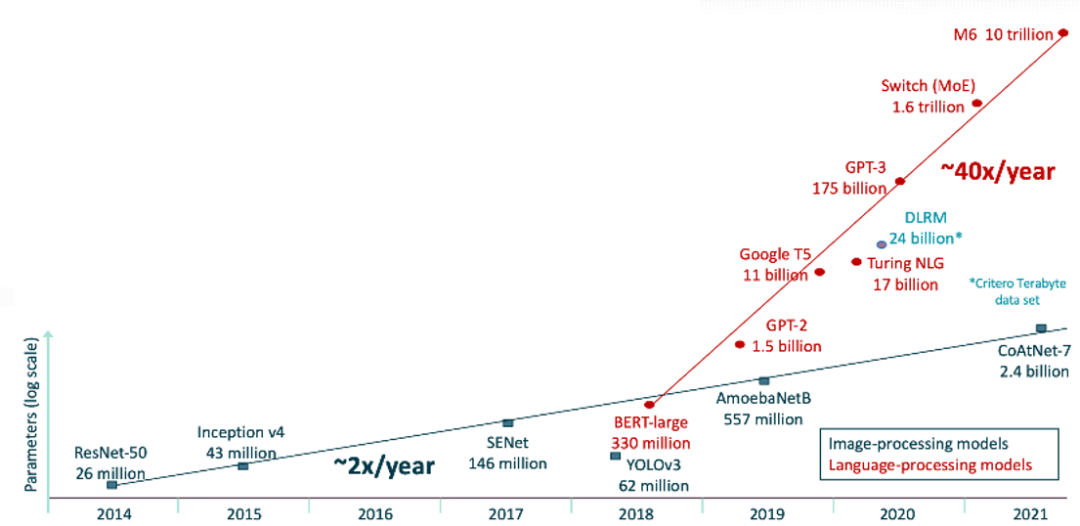
一如既往,成像模型以每年约 2 倍的规模增长,但已经达到了收益递减的位置:模型规模增长幅度非常大,而其准确度只是略微提高。成像模型通常使用 224x224 像素的 ImageNet 图像引用。与高清或 4K 图像相比,这种像素水平极低。高清图像 (1080p) 所需的处理量是 ImageNet 图像的 40 倍,而 4K 图像则需要 160 倍的处理量。
大型 NLP 模型已在处理更复杂的任务,如英译汉或创建文章摘要。这些模型非常庞大,而且还在以每年 40 倍的速度增长。最大的模型现在有多达 10 万亿的权重。模型大小受到所需的训练资源(时间和 GPU)的限制。例如,训练 GPT-3 需要使用 1024 个 NVIDIA A100 GPU 运行一个月,成本高达 2500 万美元。目前业界正在努力探索如何在不需要更多周期的情况下提高模型的准确性。其中一条规则是 “大不一定就好”——例如,DeepMind 的 Retro 模型只用 70 亿个参数就打败了 GPT-3的1750 亿个参数。
2、数据类型变得越来越小
神经网络令人惊奇的一点是,数据类型可以变得非常之小,同时不会损失准确度,不仅有 8 位,还有 4 位甚至 2 位。NVIDIA 最近发布的 Hopper 是第一个 FP8 设计。有两种不同的 FP8 格式:具有 5 位指数和 2 位尾数的 E5M2(加上隐藏位,因为尾数总是以 1 开始),和具有 4 位指数和 3 位尾数的 E4M3。似乎这些精度非常低的 FP8 格式在非常大的模型中效果最好。其他模型则不能很好地容忍这些格式。

3、稀疏计算被越来越多地使用
这可以避免在输入为零时进行 MAC 操作。NVIDIA 的 Ampere 甚至可以重新安排计算,丢弃 4 个系数中的 2 个,如果被丢弃的权重接近于零,就可以使吞吐量翻倍,而且准确度不会有所损失。
其他三种方法包括——
尖峰神经网络 (SNN):其运作方式更像大脑中的神经细胞,只使用简单的计数器和一个加法器,没有 MAC,功耗要低得多。BrainChip、GrAI Matter、Inatyera 和 Intel 等公司都在尝试这种方法。
模拟计算:模拟计算大大降低了功耗,幅度可高达 99%。最流行的方法是内存内计算 (in-memory compute)。模拟变化会降低准确度。使用这种方法的公司包括 Ambient、IBM、Mything 和 TetraMem,尽管这些公司都还没有发布生产产品。
光子学:可以将功耗降低 10 倍之多。大型光学收缩阵列可以有效地让数据流动。致力于该方法的公司包括 Lightelligence、Luminous 等。
数据中心方面的新进展
与之前的 A100 相比,NVIDIA 最近发布的 Hopper H100 的 TOPS 性能是前者的三倍,让大多数 AI 模型实现了 2.5 倍性能提升。还有一个新的系统级 NVLink,对于参数大于 1000 亿的模型来说,性能可提高 6-9 倍——但这是以功耗为代价的,耗散功率可高达 700W。
数据中心客户并不在意功耗,他们关心的是能源效率。——NVIDIA 首席执行官 黄仁勋
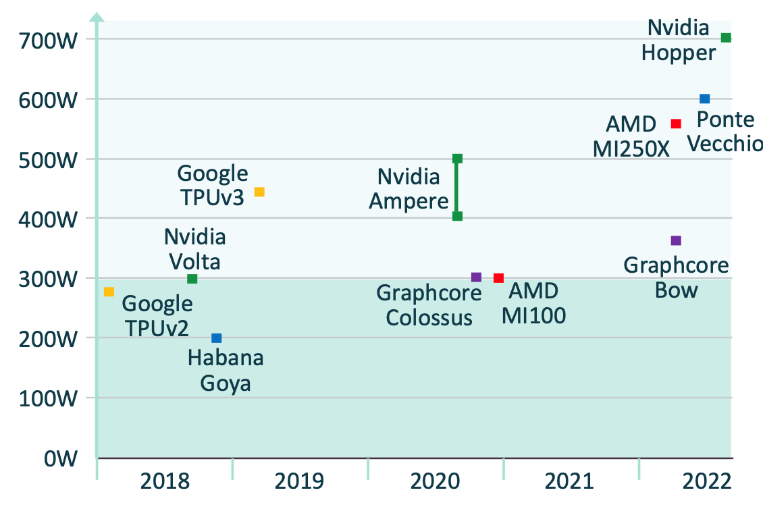
从上图可以看出,虽然 Hopper 的功耗最高,但其他很多产品的功耗都与之不相上下。
在能效方面,Qualcomm Cloud AI 100 每张卡的功耗为 75W,且机架占用空间很小。Hopper H100 将提供更高的性能,但无法缩小能效之间的差距。不过,人工智能只处理推理任务,不处理训练任务。
Graphcore Bow 使用晶圆对晶圆 (Wafer-On-Wafer) 技术来堆叠两个裸片。由于有大量的深沟电容,配电网络有更多的余量,Grapcore Colossus 裸片实现了 40% 的时钟速度提升,同时电压降低了 10%。
Linley 提到了两款做到极致的芯片:Cerebras 的晶圆级芯片和 Tesla 的 Dojo 芯片。这两款芯片都没有公开的基准测试结果。
此外,数据中心 CPU 正在增加人工智能引擎,TOPS 性能可观(即便没有独立的解决方案那么高):
这些处理器是基础处理器的“免费赠品”,因此它们适合偶尔运行人工智能任务、运行小型模型和混合工作负载。
边缘人工智能技术的新进展
有一些处理器专门面向高端应用:自动驾驶汽车和多摄像头监控系统
面向要求较低的应用的单摄像头芯片备受欢迎
在 IP 领域(与实际芯片相对立),有许多初创公司
与此同时,Cadence 已于4月推出了新的 NNE110 加速器。
甚至微控制器也开始紧跟人工智能的浪潮。当然,对于简单的网络,它们可以直接在微控制器的软件中运行。但一些嵌入式微控制器包含了矢量扩展或 AI 加速。
总结
(文章来源公众号: Cadence楷登PCB及封装资源中心)
··································································································································································································································································
关于搏嵌电子
上海搏嵌电子技术有限公司(Shanghai BoardChain Electronics Technology Co., Ltd.),是一家专注于从事电子设计自动化(EDA)服务的高科技公司。
作为Cadence授权的渠道伙伴,搏嵌电子致力于服务客户的整个电子设计流程,在原理图和PCB设计、功能验证、模拟仿真等方面为客户提供高效的技术解决方案和专业的研发工具,加速客户的产品上市周期,提升客户产品的可靠性。搏嵌的核心团队10多年来,在消费电子、半导体、通讯、汽车电子、航空航天、物联网,工业控制、医疗器械、家电、5G产业链等众多领域服务了数千家客户。

欢迎关注“搏嵌电子”公众号
了解更多Cadence EDA技术分享

