对于大大小小的制造商而言,计算流体动力学(CFD)是其工作流程的重要组成部分。工程师们使用 CFD 技术解决各种问题,包括车辆空气动力性能建模、降低 HVAC 系统噪音、模拟变速箱中的油流等。
在汽车设计中,优化至关重要。制造商竞争的不仅是设计的美观度,还有设计的效率。空气动力学专家需要预测各种车身设计变动对阻力的影响,对虚拟风洞进行建模,以最大限度地提高燃油效率或增加电动汽车(EV)的续航里程。他们还需要进行气动噪声模拟,以最大限度地降低车内噪音。他们必须开发 "畅销的造型",同时满足紧迫的项目期限,并满足与碰撞、噪声和冷却等其他 CAE 学科相关的目标和限制。
CFD 对速度的需求
高保真 CFD 仿真所面临的挑战是计算密集度极高。一次仿真可能涉及数亿个节点或单元的模型。此外,仿真通常要在由功能强大的服务器组成的集群上进行数十万甚至数百万个时间步。
在传统的基于 CPU 的求解器中,模型在内核、网络端口和计算节点间并行,依靠 MPI 和高性能互连在模型的相邻区域间共享状态。模拟几秒钟的真实世界活动可能需要数天时间。一个设计需要数千个 CPU 内核小时的情况并不少见,一个设计工作可能需要 10,000 到 1,000,000 次仿真[1]。
GPU 原生模拟器时代来临
虽然 GPU 加速 CFD 求解器已问世多年,但在过去,一些实际因素限制了其应用。尽管基于 GPU 的算法具有明显的性能优势,但其功能并不总是与基于 CPU 的求解器相当,而且模型通常太大,无法在 GPU 可用内存中运行。由于这些限制,GPU 有时只能用于较小的工作负载。
Altair的CFD晶格玻尔兹曼法(LBM)求解器、ultraFluidX® 和英伟达(NVIDIA)公司最新的数据中心GPU使这种情况发生了巨大变化。LBM 求解器非常适合基于 GPU 的高效实现,因为它们具有高度并行性,可以在每个时间步长内计算格子中所有点的密度和速度。该求解器支持涉及旋转几何体的复杂模拟[2],是高保真空气动力学和空气声学应用案例的理想选择。
用于空气动力学仿真的英伟达™(NVIDIA®)Hopper™处理器
基于英伟达™(NVIDIA®)Hopper™架构的英伟达™(NVIDIA®)H100 Tensor Core GPU于2022年3月发布,为要求苛刻的CFD工作负载提供了突破性的浮点运算性能。该卡的PCIe版本拥有多达18,432个FP32 CUDA内核,GPU有三种不同的配置[3]可供选择:
- H100 PCIe:提供 26/51 teraFLOPS 的 FP32/FP64 性能(PCIe 5.0 插槽)[4]
- H100 SXM:提供 34/67 teraFLOPS 的 FP32/FP64 性能(NVIDIA NVLink™ 互连)
- H100 NVL:提供 68/145 teraFLOPS 的 FP32/FP64 性能 [5]
H100 接替了2019年推出的英伟达安培架构(英伟达A100)。根据硬件OEM的不同,客户可以在每台服务器上运行4或8个H100 GPU。H100 SXM和H100 PCIe卡各支持80千兆字节的高带宽内存(HBM),每台服务器最多可支持8块H100卡,从而使生产规模的CFD工作负载能够在一台机器上运行。
基准测试结果
Altair 的 ultraFluidX® 团队最近对最新的NVIDIA H100 GPU进行了测试。他们在两块英伟达™(NVIDIA®)H100 PCIe显卡上运行了多个生产规模的空气动力学和空气声学工作负载,每块显卡都配备了80GB内存。测试结果与在装有上一代英伟达 A100 SXM 显卡的服务器上运行的相同测试结果进行了比较[6]。
由于 SXM型号使用了英伟达™(NVIDIA®)NVLink™,因此这并不是严格意义上的同类相比。如果有 NVIDIA H100 SXM 版显卡可供测试,结果会更好,但结果仍然令人印象深刻[7]。
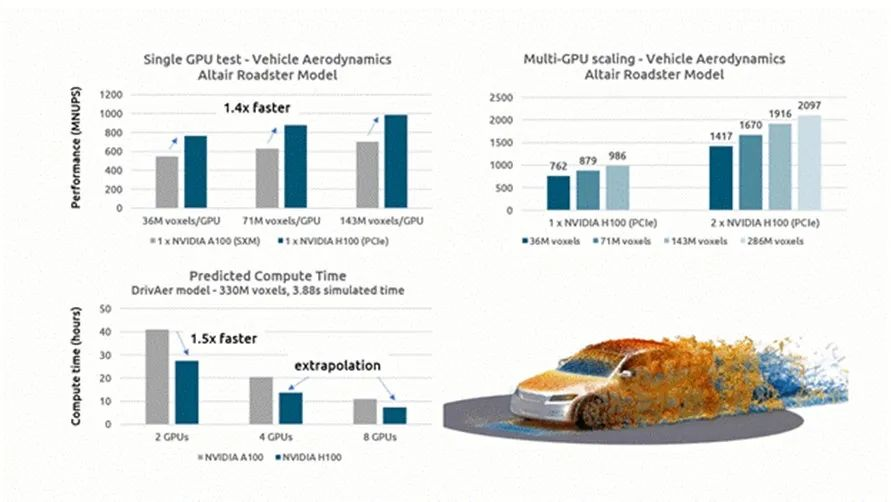
在最初的测试中,Altair 团队运行了一个专有的车辆空气动力学基准测试(Altair Roadster),比较了单个 NVIDIA A100 SXM 与新的 NVIDIA H100 PCIe 显卡在两个 GPU 上运行不同网格大小时的性能。英伟达™(NVIDIA®)H100 显卡在每种模型尺寸下的吞吐量始终高出约 1.4 倍,如下图所示[8]。
每次仿真的结果均以每秒数百万次节点更新(MNUPS)为单位绘制。在运行 1.43 亿格子模型时,英伟达 H100 GPU 的节点更新速度达到了惊人的每秒 10 亿次。
接下来,在单个和双个英伟达 H100 PCIe 配置上以不同的网格大小运行相同的模型,以评估仿真在多个 GPU 上的扩展情况。如上图所示,当添加第二个 GPU 时,每个模型每秒节点更新的吞吐量几乎翻了一番,提供了 ~93% 到 ~97% [9]的强大扩展效率。
量产测试
接下来,Altair 使用量产级 DrivAer 验证测试版本进行了更广泛的空气动力学仿真。该测试涉及车辆表面 1.5 毫米的网格,在 3.88 秒的物理时间内模拟出 3.3 亿个格子模型。包括网格划分所需的时间在内,这项全面测试在 2 路、4 路和 8 路英伟达 A100 SXM GPU 配置上重复进行。使用 2 个 GPU 时,模拟运行时间超过 40 小时,使用 8 个 A100 GPU 时,模型运行时间约为 12 小时。
虽然只有两块 H100 GPU 可用于测试,但通过推断 A100 SXM 测试的结果并应用观察到的多 GPU 缩放因子,DrivAer 测试使用八块英伟达™(NVIDIA®)H100 GPU的预测解算时间不到八小时。
对于运行大规模仿真驱动设计的网站来说,这样的性能水平足以改变游戏规则。使用最新英伟达™(NVIDIA®)H100 GPU进行的初步测试表明,工程师可以在单台服务器上使用 ultraFluidX 轻松地运行高保真仿真一夜——这是以前无法达到的性能水平,将显著提高CAE设计环境的效率。我们期待着在 NVIDIA H100 SXM 显卡进行硬件测试后,对这些结果进行验证。
针对不同工作量的求解器系列
Altair CFD为各种流体力学问题提供了一整套基于CPU和GPU的求解器。产品组合中的求解器包括Altair® AcuSolve®(通用纳维-斯托克斯求解器)、Altair® nanoFluidX®(光滑粒子流体力学求解器)和Altair® ultraFluidX(上述测试中使用的LBM求解器)。
客户还可以利用Altair® Inspire™ Studio与GPU加速的Altair TheaRender™和Paraview,缩短渲染高质量无噪声图像所需的时间。这些 Altair 解决方案可以在各种NVIDIA平台和GPU上运行,包括NVIDIA RTX工作站、NVIDIA DGX平台以及基于NVIDIA GPU的OEM解决方案。
结论
传统的基于CPU的仿真可能需要很长时间才能完成,这阻碍了制造商探索设计参数并获得最佳解决方案的能力。
使用 Altair 工具,空气动力学专家和工程师可以完全自动化他们的工作流程——从在Inspire Studio中建立模型到使用Altair® HyperMesh®进行网格划分,再到将模型导入Altair® Virtual Wind Tunnel™。从那里,他们可以向基于GPU的集群提交作业,然后使用Altair® Access™进行无缝后处理和可视化结果。
英伟达™(NVIDIA®)H100 的这些早期结果表明,为整车空气动力学运行通宵瞬态仿真的能力改变了制造商的游戏规则。利用英伟达™(NVIDIA®)H100 GPU 和 ultraFluidX,设计人员可以更快地进行迭代,创建质量更高、性能更好的设计,并对设计进行更全面的仿真,从而获得更好的结果,并消除设计过程中的风险。
参考资料:
[1] See the NVIDIA article: The Computational Fluid Dynamics Revolution Driven by GPU Acceleration.
[2] Large Eddy Simulations (LES) is a cutting-edge technique used in the aerospace and automobile industries to simulate how hardware interacts with fluids.
[3] SeeNVIDIA H100 Tensor Core GPU Architecture, page 18, for detailed specifications.
[4] See NVIDIA H100 Tensor Core GPU technical specifications
[5] The H100 NVL comprises two PCIe 5.0 cards paired with an NVLink bridge.
[6] Unfortunately, at the time these tests were run, the H100 SXM was not available for testing. Altair and NVIDIA expect to run additional benchmarks in future.
[7] See the NVIDIA H100 datasheetfor additional information. The H100 SXM delivers 67 teraFLOPS of FP64 performance vs. 51 teraFLOPS for the H100 PCIe card. NVLink on the A100 SXM has an interconnect bandwidth of 600 GB/s vs. 128 GB/s for PCIe Gen 5.
[8] The model size is represented in voxels, generic units representative of a volume of 3D space computed when the model is meshed.
[9] Strong scaling refers to the improvement in time required to solve a fixed-size problem as the number of GPUs increases. For the 36M voxel test, the dual GPU configuration delivered 1,417 MNUPS vs. 762 MUPS for the single GPU configuration. (1417/762)/2 = 93.0% scaling efficiency. For the 143M voxel test, the dual GPU configuration delivered 1,916 MNUPS vs. 986 MUPS for the single GPU configuration. (1916/986)/2 = 97.2% scaling efficiency. Astute readers will notice that there was also an improvement in “weak scaling,” defined as the time required for a fixed unit of work to complete as the problem size is increased. Due to memory limitations, the 286 million voxel model was not run on a single GPU configuration
(文章来源公众号: Altair澳汰尔)
 400-0519-668
400-0519-668